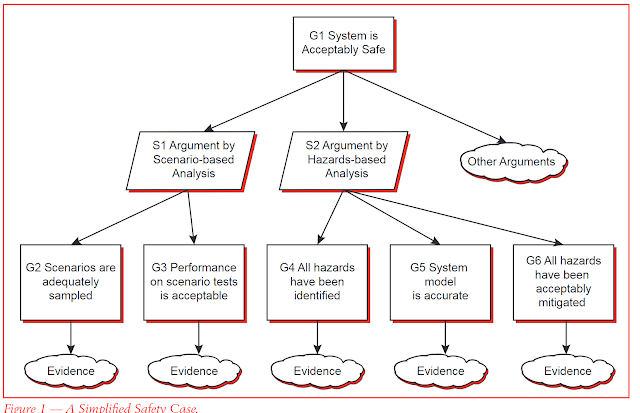
SPIs help ensure that assumptions in the safety case are valid, that risks are being mitigated as effectively as you thought they would be, and that fault and failure responses are actually working the way you thought they would.
Safety Performance Indicators, or SPIs, are safety metrics defined in the Underwriters Laboratories 4600 standard. The 4600 SPI approach covers a number of different ways to approach safety metrics for a self-driving car, divided into several categories.
One type of 4600 SPI safety metric is a system-level safety metric. Some of these are lagging metrics such as the number of collisions, injuries and fatalities. But others have some leading metric characteristics because while they’re taken during deployment, they’re intended to predict loss events. Examples of these are incidents for which no loss occurs, sometimes called near misses or near hits, and the number of traffic rule violations. While by definition, neither of these actually results in a loss, it’s a pretty good bet that if you have many, many near misses and many traffic-rule infractions, eventually something worse will happen.
Another type of 4600 metric is intended to deal with ineffective risk mitigation. An important type of SPI relates to measuring that hazards and faults are not occurring more frequently than expected in the field.
Here’s a narrow but concrete example. Let’s assume your design takes into account that you might lose one in a million network packets due to corrupted data being detected. But out in the field, you’re dropping every tenth network packet. Something’s clearly wrong, and it’s a pretty good chance that undetected errors are slipping through. You need to do something about that situation to maintain safety.
A broader example is that a very rare hazard might be deemed not to be risky because it just essentially never happens. But just because you think it almost never happens doesn’t mean that’s what happens in the real world. You need to take data to make sure that something you thought would happen to one vehicle in the fleet every hundred years isn’t in fact happening every day to someone, because if that’s the case, you badly misestimated your risk.
Another type of SPI for field data is measuring how often components fail or behave badly. For example, you might have two redundant computers so that if one crashes, the other one will keep working. Consider one of those computers is failing every 10 minutes. You might drive around for an entire day and not really notice there’s a problem because there’s always a second computer there for you. But if your calculations assume a failure once a year and it’s failing every 10 minutes, you’re going to get unlucky and have both fail at the same time a lot sooner than you expected.
So it’s important to know that you have an underlying problem, even though it’s being masked by the fault tolerance strategy.
A related type of SPI has to do with classification algorithm performance for self-driving cars. When you’re doing your safety analysis, it’s likely you’re assuming certain false positive and false negative rates for your perception system. But just because you see those in testing doesn’t mean you’ll see those in the real world, especially if the operational design domain changes and new things pop up that you didn’t train on. So you need a SPI to monitor the false negative and false positive rates to make sure that they don’t change from what you expected.
Now, you might be asking, how do you figure out false negatives if you didn’t see it? But in fact, there’s a way to approach this problem with automatic detection. Let’s say that you have three different types of sensors for redundancy and you vote three sensors and go with the majority. Well, that means every once in a while, one of the sensors can be wrong and you still get safe behavior. But what you want to do is take a measurement of how often the one wrong happens, because if it happens frequently, or the faults on that sensor correlate with certain types of objects, those are important things to know to make sure your safety case is still valid.
A third type of 4600 metric is intended to measure how often surprises are encountered. There’s another segment on surprises, but examples are the frequency at which an object is classified with poor confidence, or a safety relevant object flickers between classifications. These give you a hint that something is wrong with your perception system, and that it’s struggling with some type of object. If this happens constantly, then that indicates a problem with the perception system. It might indicate that the environment has changed and includes novel objects not accounted for by training data. Either way, monitoring for excessive perception issues is important to know that your perception performance is degraded, even if an underlying tracking system or other mechanism is keeping your system safe.
A fourth type of 4600 metric is related to recoveries from faults and failures. It is common to argue that safety-critical systems are in fact safe because they use fail-safes and fall-back operational modes. So if something bad happens, you argue that the system will do something safe. It’s good to have metrics that measure how often those mechanisms are in fact invoked, because if they’re invoked more often than you expected, you might be taking more risks than you thought. It’s also important to measure how often they actually work. Nothing’s going to be perfect. And if you’re assuming they work 99% of the time but they only work 90% of the time, that dramatically changes your safety calculations.
It’s useful to differentiate between two related concepts. One is safety performance indicators, SPIs, which is what I’ve been talking about. But another concept is key performance indicators, KPIs. KPIs are used in project management and are very useful to try and measure product performance and utility provided to the customer. KPIs are a great way of tracking whether you’re making progress on the intended functionality and the general product quality, but not every KPI is useful for safety. For example, a KPI for a fuel economy is great stuff, but normally it doesn’t have that much to do with safety.
In contrast, an SPI is supposed to be something that’s directly traced to parts of the safety case and provides evidence for the safety case. Different types of SPIs include making sure the assumptions in the safety case are valid, that risks are being mitigated as effectively as you thought they would be, and that fault and failure responses are actually working the way you thought they would. Overall, SPIs have more to do with whether the safety case is valid and the rate of unknown surprise arrivals is tolerable. All these areas need to be addressed one way or another to deploy a safe self-driving car.